Release Notes v2.4 (July 2022)
The new features that have been included in Code Ocean 2.4 are:
New Pipelines Feature
In this version, we are introducing an automated pipelines tool that allows users to connect multiple capsules in a drag-and-drop interface that any collaborator can use. This is a new and seamless experience of building, testing and running pipelines of capsules without writing NextFlow and without knowing AWS Batch.
This feature provides:
An easy way to configure parallel computing and memory requirements for each step in the pipeline.
The ability to swap capsules or adjust parameters within individual capsules if a different methodology is needed at any step.
Automatic generation of Nextflow scripts to run the pipeline you create.
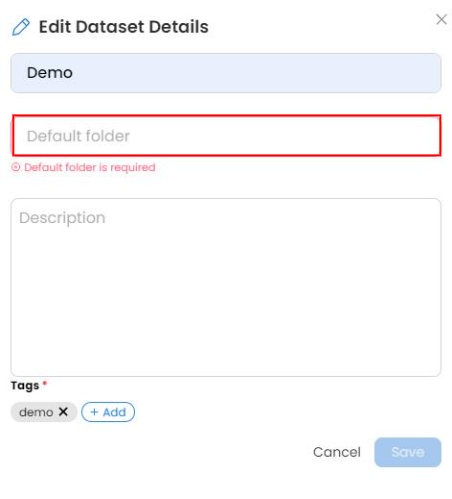
Edit Feature in Data Assets
Edit now allows you to change the "Default folder" information, which is the folder name that will appear in the capsule file tree after a Data Asset has been attached to a Capsule.
Note: in contrast to the Data Asset Name, the Default Folder needs to have a name that is acceptable by a Linux file system, meaning the Default Folder Name may contain letters (A-Z, a-z), numbers (0-9), underscore (_), dash (-).
App Panel Parameter Settings
The App Panel now allows the setting of parameters without a default value.
Reproducible Run Returns to Timeline
When a Reproducible Run completes, it returns to the Timeline instead of staying in the Info Progress Bar.
Imported Base Images (Gallery Capsules) Made Available
When a user duplicates a gallery capsule with base images that are not already in their VPC, the information of that base image will appear in the Starter Environment list on the Admin panel with an Imported label.
This allows admins to deploy the imported base image or make it available in the VPC, so that more development can be implemented with this base image.
Scratch Folder Availability for Reproducible Run
The scratch folder, previously only accessible via Cloud Workstation, is now available for Reproducible Run.
The purpose is twofold:
To ensure code that runs in Cloud Workstation will run the same in Reproducible Run
To provide computations a place to store large intermediate files generated during Reproducible Run, and avoid impacting performance or exceeding capsule size limitations.
The scratch folder for Reproducible Run behaves differently from the scratch folder in the Cloud Workstation and is designed for reproducibility purposes. It is a temporary folder that is created when the computation starts and is deleted when the computation ends.
Therefore, any pre-existing files in the scratch folder will not be available during Reproducible Run, and any data generated during the Reproducible Run will not appear in the scratch folder once the run has completed.
Last updated