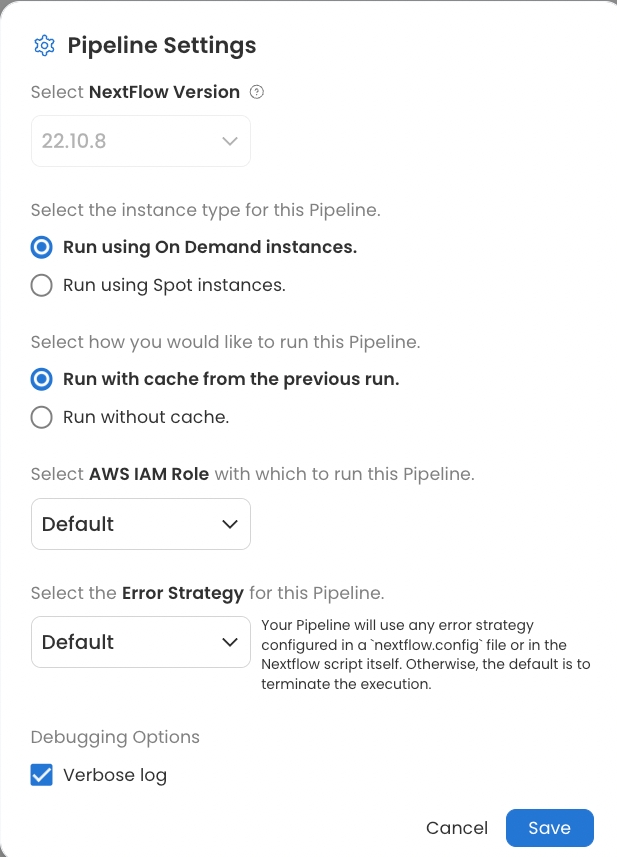
Pipeline Settings
The Pipeline Settings menu provides several options to customize how the Pipeline runs.
The following settings options are described in this guide:
Nextflow Version
Users can select the Nextflow version to run, 22.10.8 or 23.10.0, when the main.nf file is unlocked. For more information on unlocking the Nextflow file, see Nextflow File. For more information on Nextflow version, see the Nextflow documentation.
Instance Type
Users can choose to run the Pipeline using entirely On Demand or Spot instances. The default setting is On Demand, but users can select Spot instances to save money on compute resources. See Compute Resources for more information.
Run with Cache
This option allows users to decide whether or not the Pipeline should run using cached data from a previous run. By default, the Pipeline runs with cache, which automatically resumes the run at the first step in the Pipeline where a change has been made.
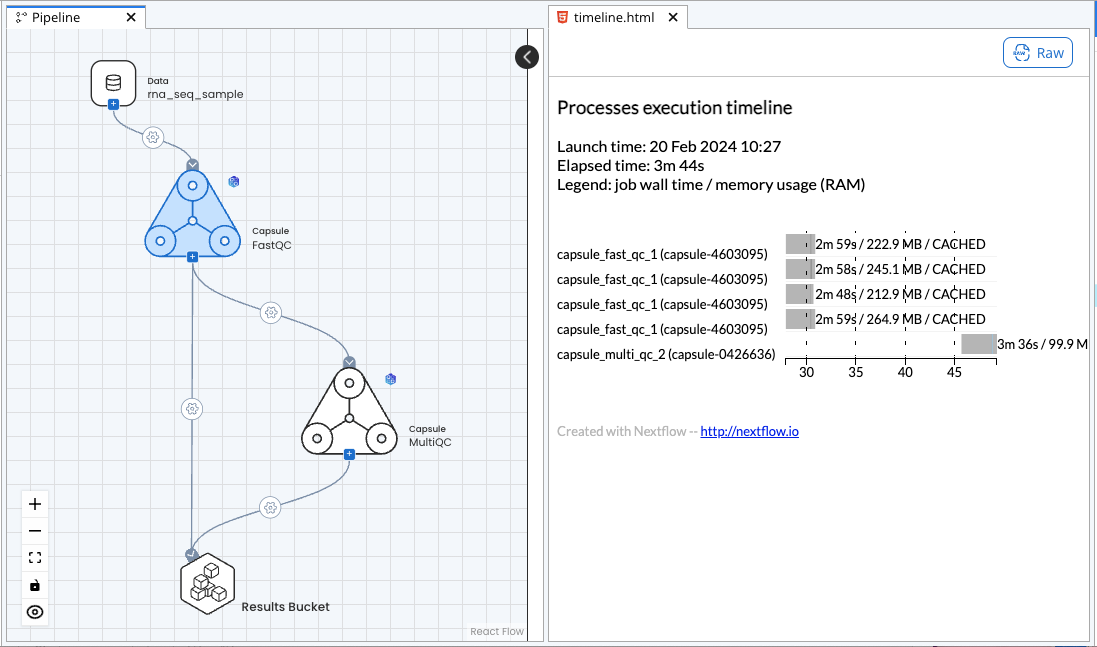
For example, in the Pipeline below, if the Map Paths menu between FastQC and MultiQC has been changed but the inputs and outputs of FastQC have not changed, users can resume the run and the Pipeline will start at MultiQC using the cached output of FastQC. The timeline report of the resumed run is shown below.
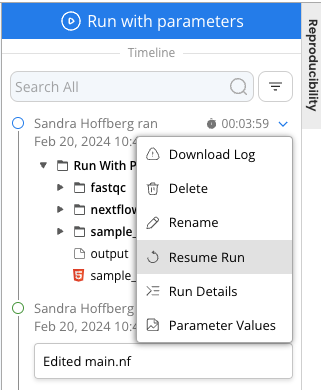
If users select "Run without cache," the Pipeline will restart from the beginning. However, cached data can still be used for an individual run by selecting "Resume Run" in the dropdown menu of a result in the Timeline.
Resuming the most recent run is equivalent to a Reproducible Run when "Run with cache from the previous run" is selected.
Performing a Reproducible Run with the cache will search for Pipeline runs with the same data, Capsule, and Map Paths. For the data to be the same, the contents of the Data Asset or local files must not have changed, including the contents of an External bucket and the mount point (folder name) must be the same. Cached data can be used from any previous run of the Pipeline even if the Pipeline has since been duplicated or other runs have been performed in the meantime. Running with cache of runs that were performed concurrently is best done with the Resume Run button.
AWS IAM Role
AWS Identity and Access Management (IAM) roles are created in AWS and assigned specific permissions so that Code Ocean (and other trusted identities) can perform actions in AWS. Pipelines run with a default IAM role.
If external Data Assets are used, users must select another role with permissions to access AWS batch and the external data. In addition, Capsules with AWS credentials as a secret require an IAM role. Admins must define these roles in AWS and provide access through an Identity Provider.
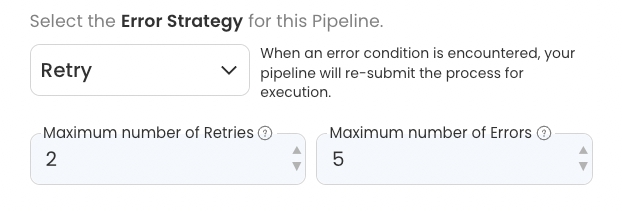
Error Strategy
To define a Pipeline's behavior when an error is encountered, users can choose among the following Nextflow error strategies:
Default: Your Pipeline will use any error strategy configured in a
nextflow.configfile or in the Nextflow script itself. Otherwise, the default is to terminate the execution.Terminate: When an error condition is encountered, your pipeline will terminate the execution and pending jobs will be killed.
Finish: When an error condition is encountered, your pipeline will initiate an orderly shutdown, pending the completion of any submitted jobs.
Ignore: When an error condition is encountered, your pipeline will ignore process execution errors.
Retry: When an error condition is encountered, your pipeline will re-submit the process for execution. The user will be able to set the minimum and maximum number of retry attempts.
Debugging Options
Unchecking the "Verbose log" box will hide the terminal output of each process.