Environment Variables
Code Ocean specific environment variables are available during Reproducible Runs and Cloud Workstation Sessions to reduce coding complexity. Users can also create their own environment variables.
User-Created Environment Variables
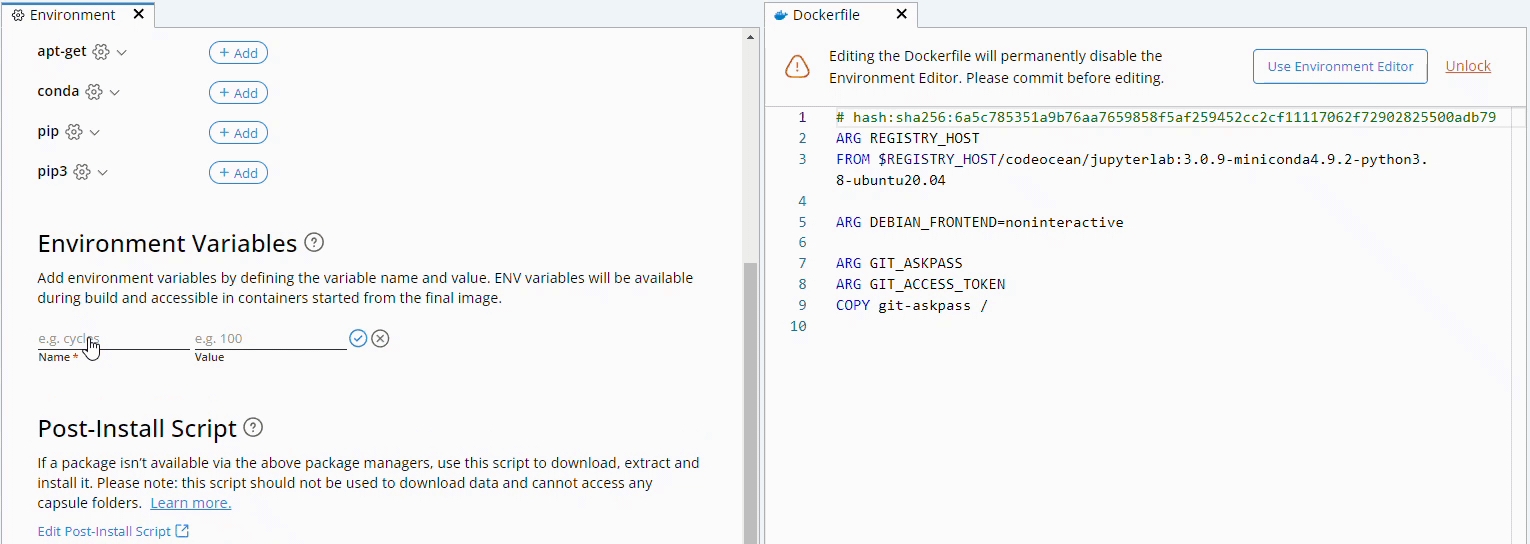
Users can define environment variables from the Environment Editor as shown below. These variables are automatically added to the Capsule's Dockerfile before the installation commands so they can be used during the environment build phase if necessary. During runtime, the reference to the variable is replaced with its value.
Environment variable names must always start with a letter or underscore ("_") and may only consist of alphanumeric characters and underscores ("_").
Environment variable names are case-insensitive meaning the names “ABC” and “abc” cannot both exist in the same Capsule.
User-created environment variables can be edited by clicking on the variable name or deleted by clicking on the X to the right of the variable as shown below.
Changing the executable PATH
The PATH is an environment variable that specifies a set of directories where executable programs are located. For programs installed by package managers, the PATH does not need to be altered. However, for programs installed in the Post-Install script, the PATH can be reassigned in the Post-Install script. This will take affect only when working in a Cloud Workstation. When performing a Reproducible Run, the PATH should be set in the Environmental Variables section of the Environment editor.
Code Ocean Specific Environmental Variables
CO_CPUS: the number of available CPU cores.
CO_MEMORY: the available RAM in bytes.
CO_COMPUTATION_ID: the unique identifier of the current computation.
CO_CAPSULE_ID: the capsule's unique identifier, also available in the metadata page.
CO_PIPELINE_ID: the pipeline's unique identifier, also available in the metadata page. Only present in a pipeline reproducible run.
GIT_ACCESS_TOKEN: only defined if a user has entered their Git credentials in the Account page.
Use in Pipelines
Each Capsule in a Pipeline will have its own CO_CPUS, CO_MEMORY, and CO_CAPSULE_ID variables but they will all share the same CO_PIPELINE_ID and CO_COMPUTATION_ID.
CO_CPUS and CO_MEMORY variables should always be used over other approaches when the CPU and memory count is used by a capsule. Since Code Ocean Pipelines run on AWS Batch, manually calculating the CPU and memory count can be inaccurate due to discrepancies between the resources a job has been allocated and the resources of the machine the job is running on.
Examples
Passing the CPU Count to FastQC
FastQC is a command line tool for quality control of sequencing reads. The following code shows how CO_CPUS can be used as an argument to accelerate the computation by leveraging all available CPUs.
Maintaining Traceability When Transferring Data to External Locations
If the result of a Capsule or Pipeline is transferred outside of Code Ocean, the CO_CAPSULE_ID/CO_PIPELINE_ID and CO_COMPUTATION_ID variables can be used to help maintain traceability. The following code shows how these variables can be saved to a text file and transferred to the same external S3 bucket where the results are saved. Saving these unique identifiers ensures reproducibility by recording the exact Capsule and computation that produced the result.