nf-core RNASeq Tutorial
This tutorial demonstrates how to run nf-core's RNAseq pipeline on Code Ocean. nf-core/rnaseq is a bioinformatics pipeline that can be used to analyse RNA sequencing data obtained from organisms with a reference genome and annotation. It takes a samplesheet and FASTQ files as input, performs quality control (QC), trimming and (pseudo-)alignment, and produces a gene expression matrix and extensive QC report.
Table of Contents
Prerequisites
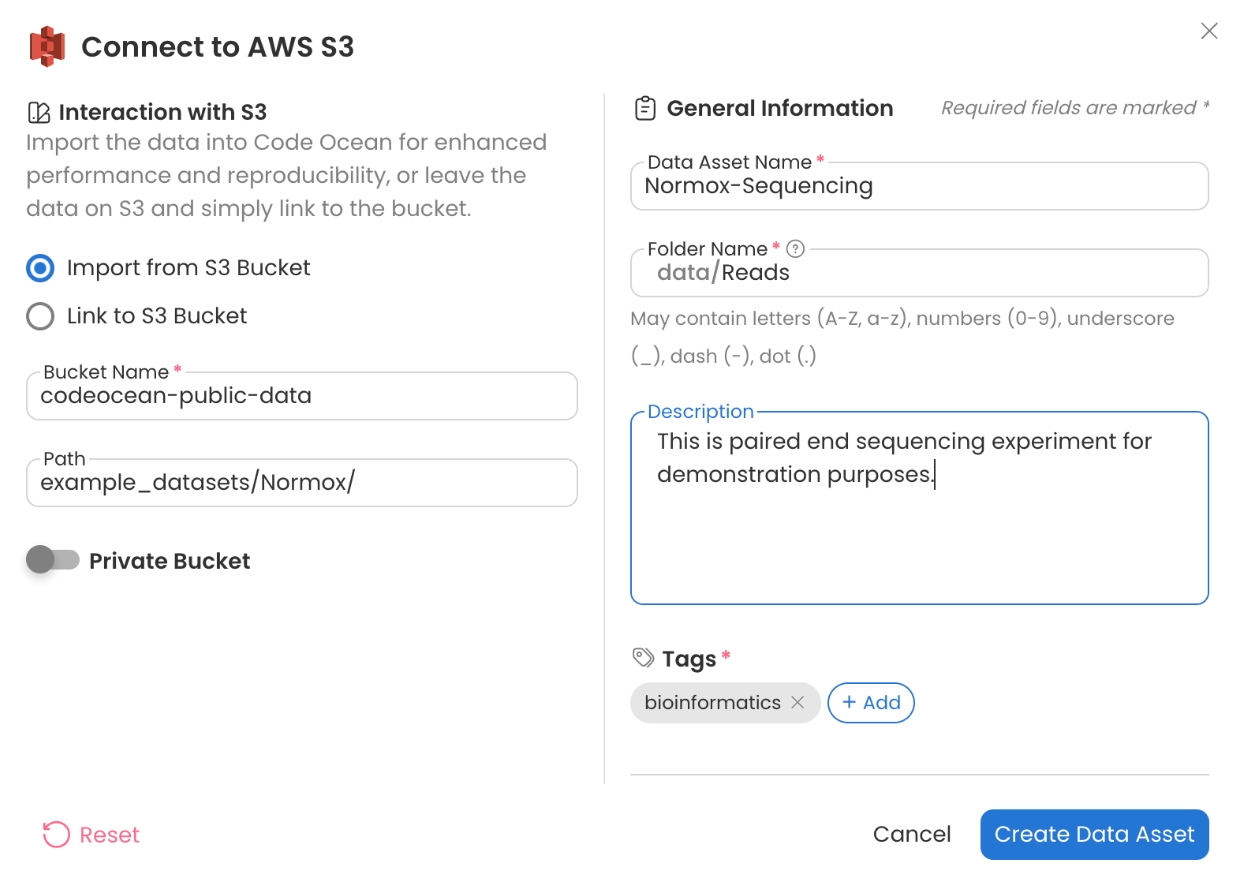
First, create an Internal Data Asset of the sequencing reads. This Data Asset can be imported from the public S3 bucket with the following bucket name and path:
We shall use the following Data Asset to demonstrate.
Example Sequencing Reads
Bucket Name: codeocean-public-data
Path: example_datasets/Normox
To use External Data Assets in a Pipeline, Assumable Roles must be configured by a Code Ocean admin.
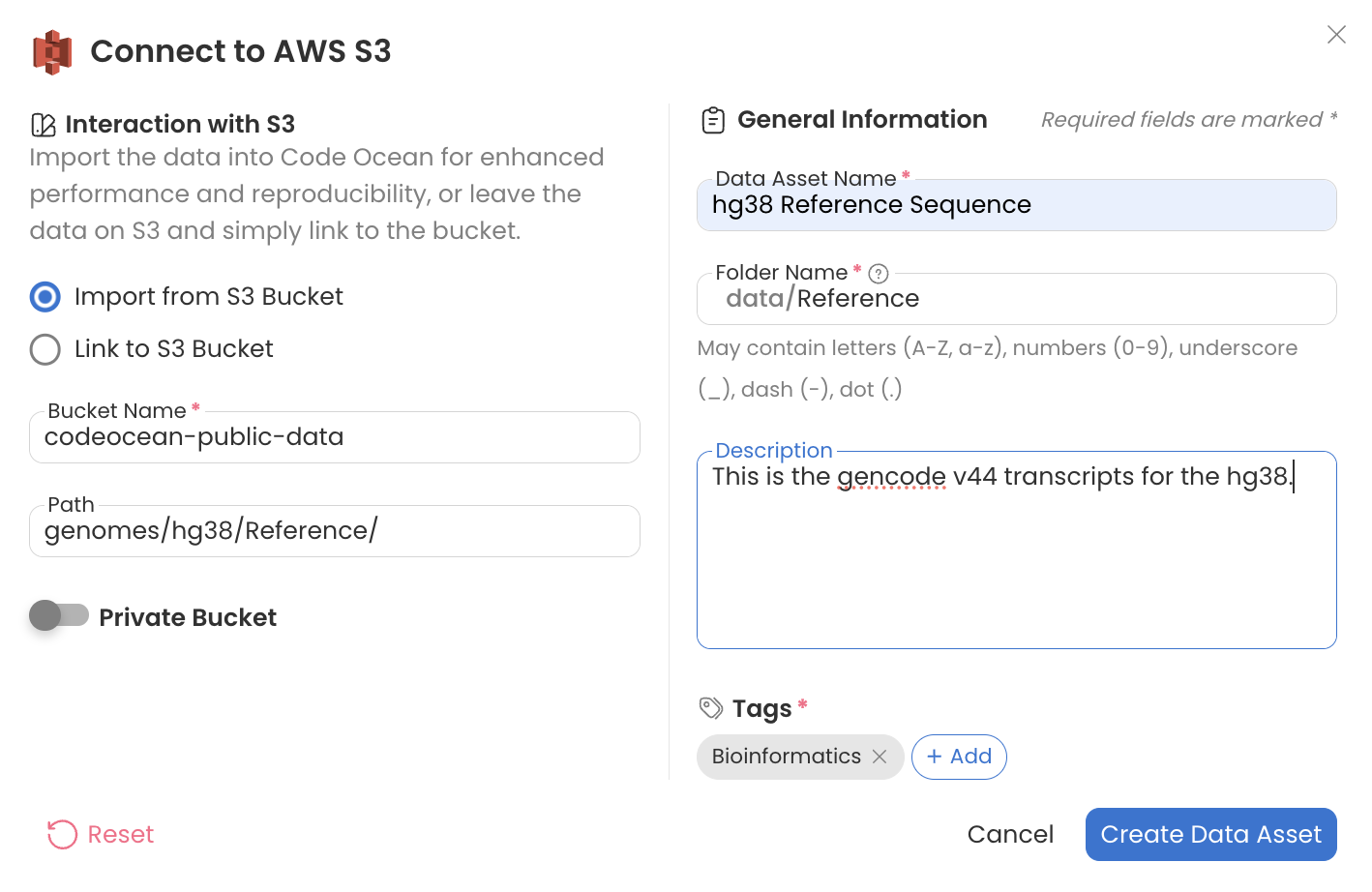
hg38 Reference Sequence
Bucket Name: codeocean-public-data
Path: genomes/hg38/Reference/
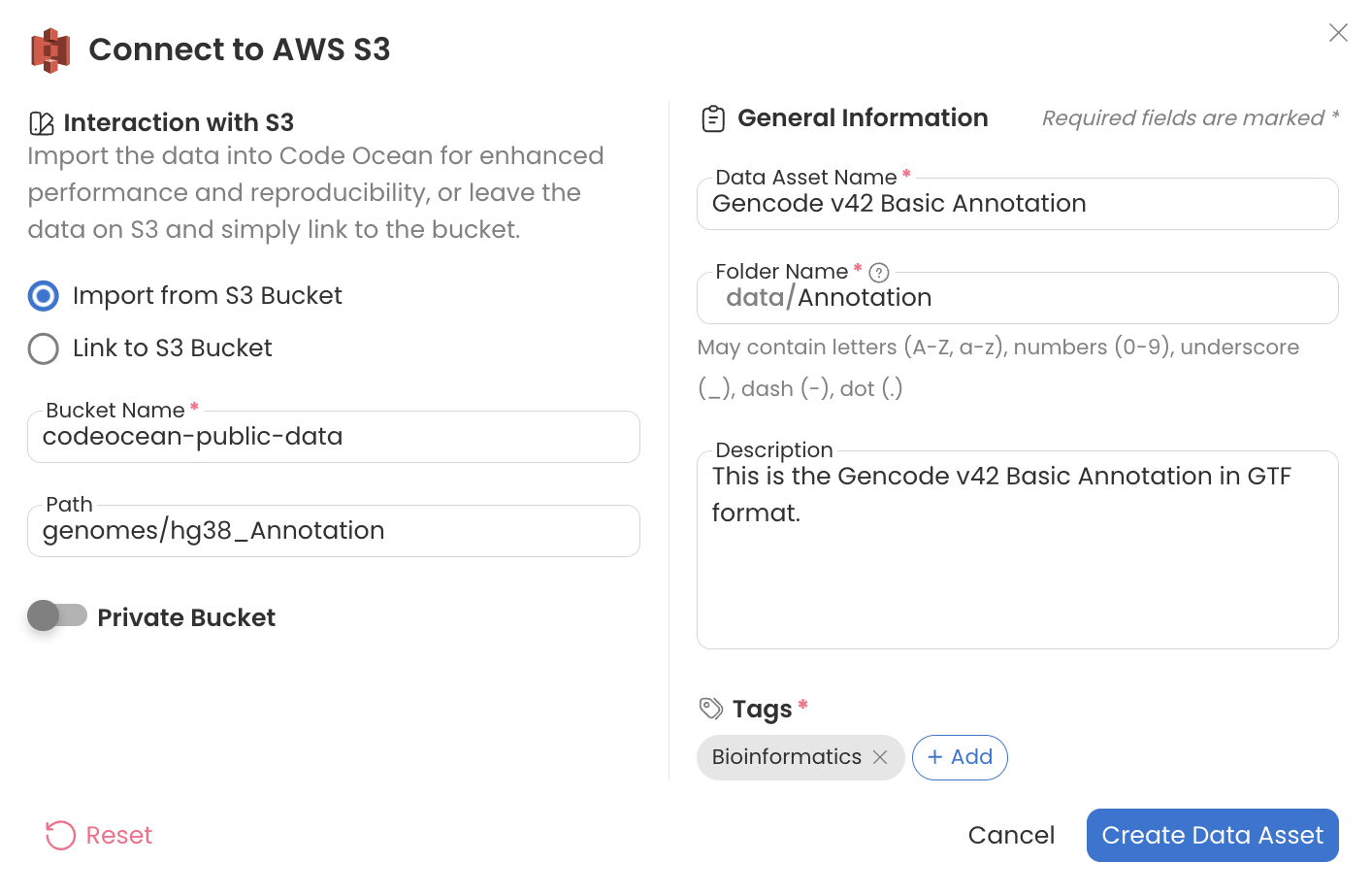
hg38 Annotation
Bucket Name: codeocean-public-data
Path: genomes/hg38_Annotation
Create the Pipeline
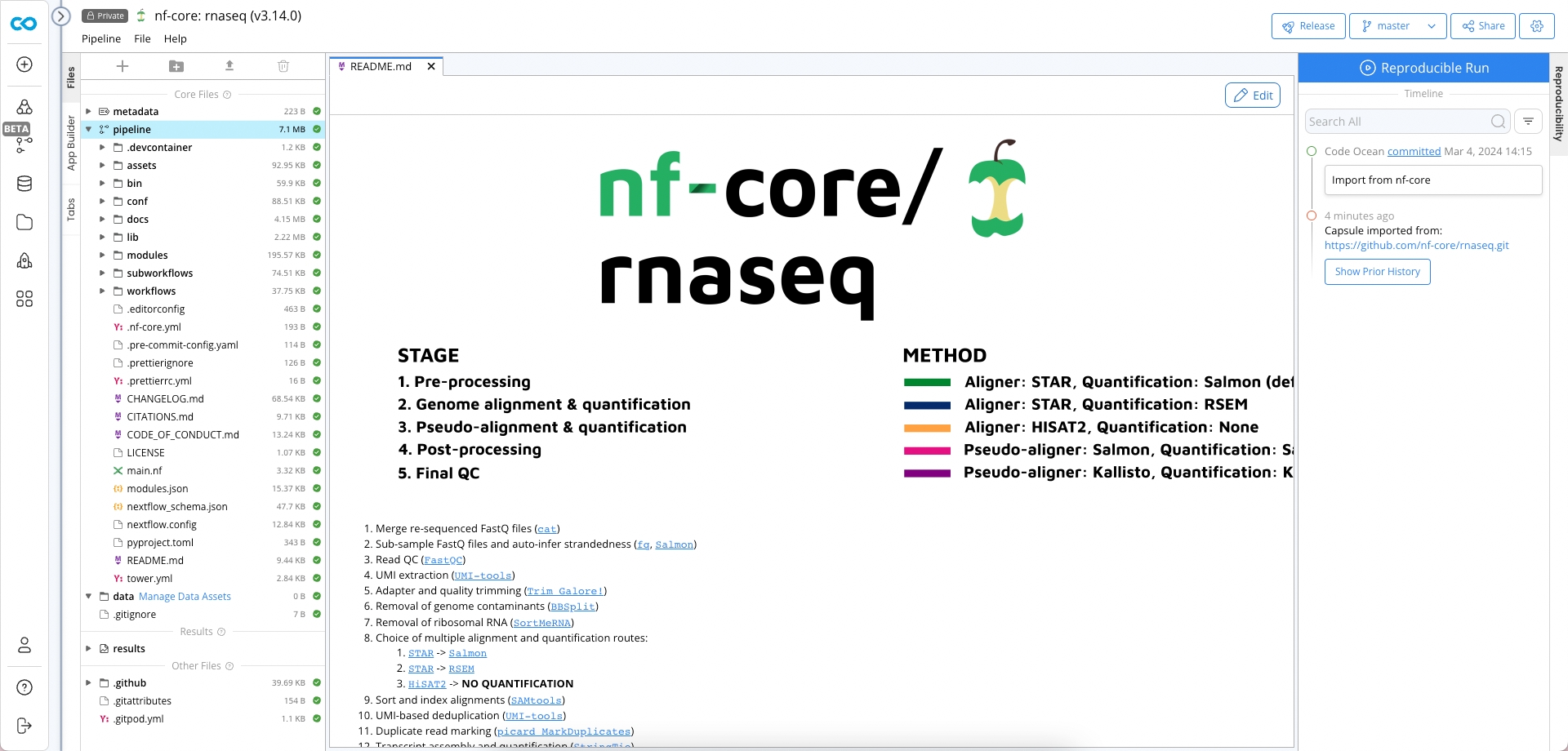
From the Sidebar, create a new Pipeline by Import from nf-core
Search for rnaseq and v3.14.0
Click on Import to import the pipeline into your deployment.
Once the pipeline has been imported you'll be greeted with its README file
Attach Data Assets to the Pipeline
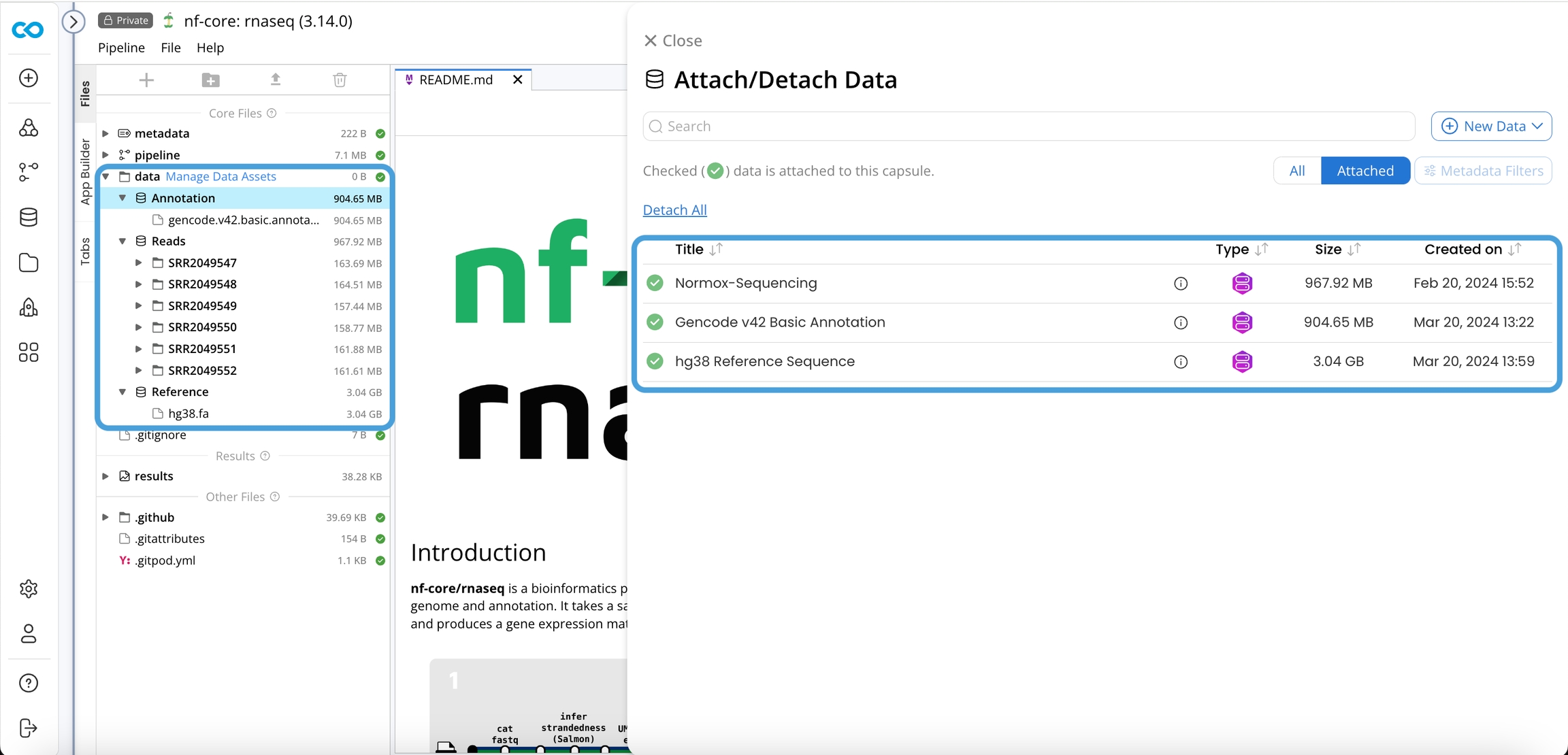
Click on Manage Data Assets
Search and Attach the following 3 Data Assets:
Normox-Sequencing
Gencode v42 Basic Annotation
hg38 Reference Sequence
Configure the Sample Sheet
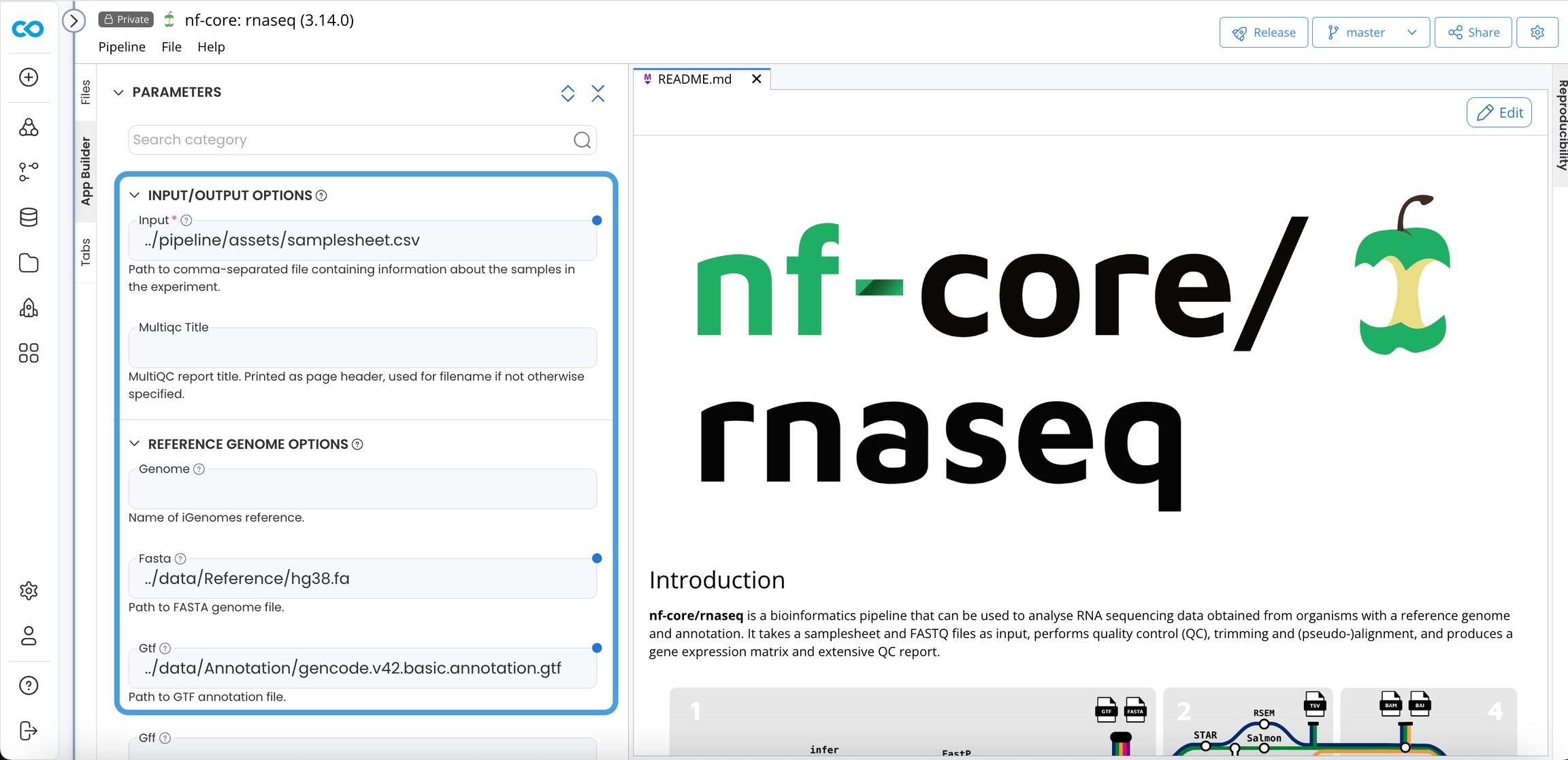
Edit the sample sheet at /pipeline/assets/samplesheet.csv to specify the sample names, location of read 1 and read 2 (if paired end), and strandedness. The strandedness refers to the library preparation and will be automatically inferred if set to auto. Must be one of unstranded, forward, reverse or auto. Rows with the same sample identifier are considered technical replicates and merged automatically.
Configure the App Panel
In the App Panel, update the Input, Fasta and Gtf parameters according to the location of your data.
Delete the value of the Igenomes Base parameter as those resources are not used in this tutorial. See iGenomes for instructions on how to use iGenomes resources.
Reproducible Run
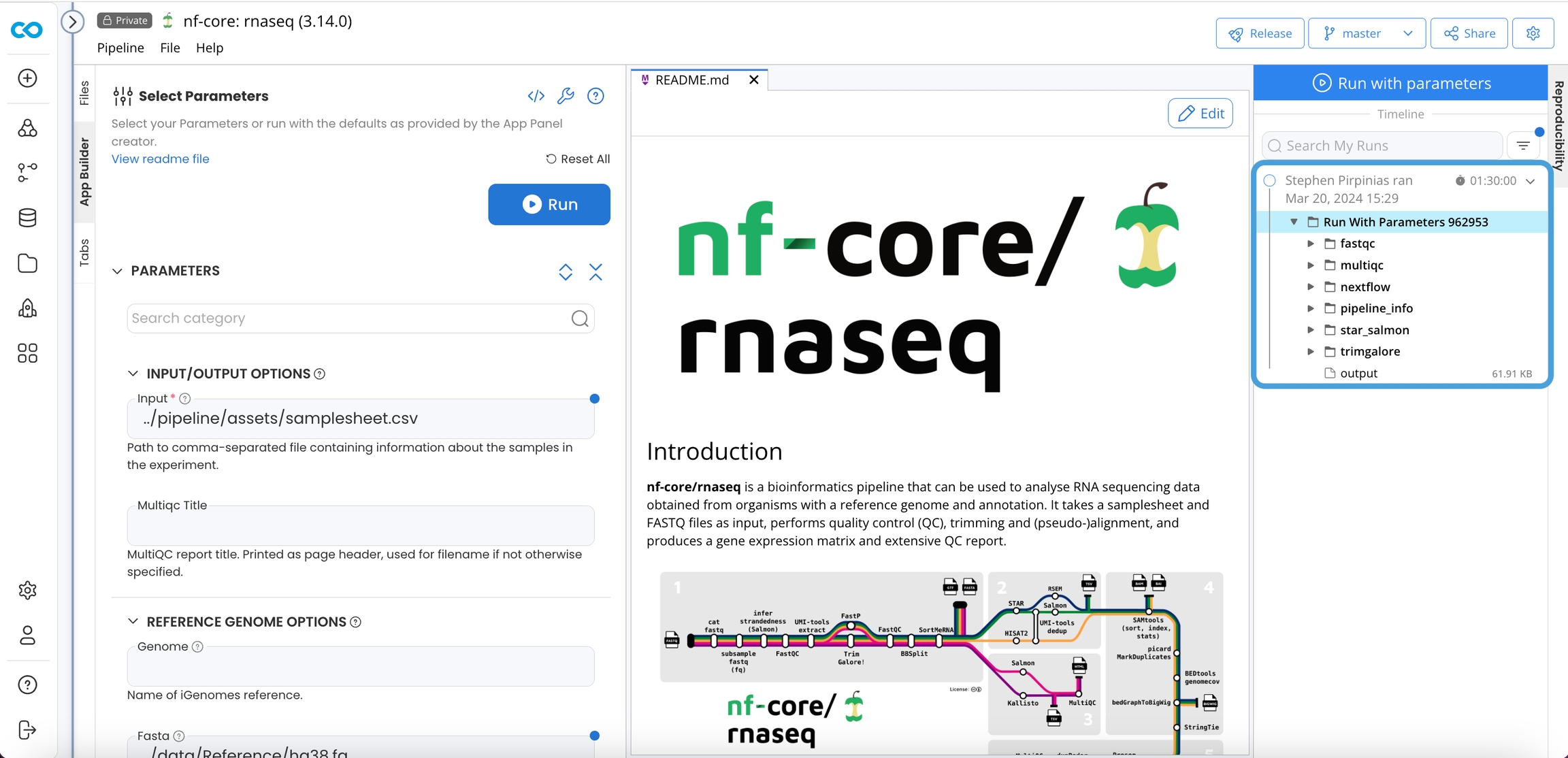
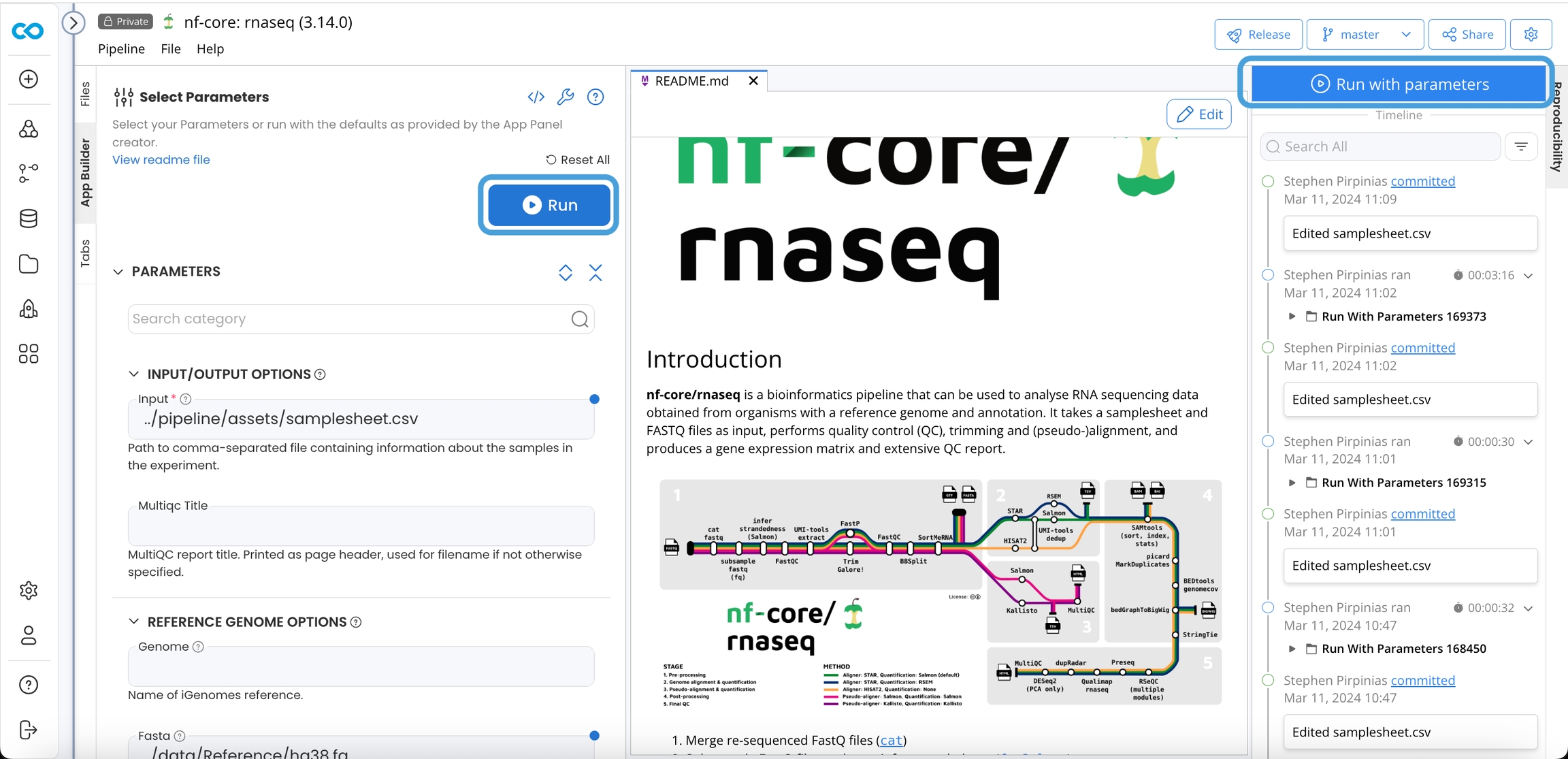
Click on Run or Run with Parameters
Results
The Results are available in the Pipeline Timeline and a Data Asset can be created for downstream processing.